|
|
Post by sushi on Feb 12, 2013 5:23:53 GMT -5
maybe the filter is a bit tight - it will exclude characters with accents - if they are used you could add them to this section of the script to be included by adding another 'elif' line that then 'return chac'. def testchac(chac): if chac>0x1F and chac<0x40: return chac #excludes @ 0x40 elif chac>0x40 and chac<0x7B: return chac elif chac==0xA9: return 0x63 #copyright chac elif chac==0x0D: return 0x40 #CR return 0 Yes I don't have the accentuated chars but in fact I don't understand what I must do to have them  I'll try to add this line
elif chac==0xE0,0xE9,0xEA,0xEB,0xF9: return chacI'm trying this one :
def testchac(chac):
if chac>0x1F and chac<0x40: return chac #excludes @ 0x40
elif chac>0x40 and chac<0x7B: return chac
elif chac==0xE0: return chac
elif chac==0xE9: return chac
elif chac==0xEA: return chac
elif chac==0xEB: return chac
elif chac==0xF9: return chac
elif chac==0xA9: return 0x63 #copyright chac;
elif chac==0x0D: return 0x40 #CR
return 0
It seems to work... I'll verify at once.So finally I used this one def testchac(chac): if chac>0x1F and chac<0x40: return chac #excludes @ 0x40 elif chac>0x40 and chac<0x7B: return chac elif chac==0xE0: return chac elif chac==0xE8: return chac elif chac==0xE9: return chac elif chac==0xEA: return chac elif chac==0xEB: return chac elif chac==0xEE: return chac elif chac==0xF4: return chac elif chac==0xF9: return chac elif chac==0xA9: return 0x63 #copyright chac; elif chac==0x0D: return 0x40 #CR return 0 It looks that everything is ok now  Thank you for your coding ! |
|
|
|
Post by duncan on Feb 12, 2013 13:51:10 GMT -5
Cool |
|
|
|
Post by sushi on Feb 12, 2013 20:44:47 GMT -5
Is it normal that i have 2x or more exactly the same translations to do on the same file to random locations, (the file you extracted). Coud you verify they are not redundant cause it is a really big job !!! Exemple : 1 920816 17 20 An Eye For An Eye Œil pour œil. 1 920836 273 276 Old Faithful here again... C'est encore moi, il s'est passé... 1 921112 10 12 All Change Tout Change In fact for all the accentuated FR characters needed the code is : if 1==1:
import array
f=open('G:\HardwarW.exe','rb')
fb = array.array('B')
start=0
end=f.seek(0,2)
dump=f.seek(0,0)
fb.fromfile(f,end-start)
f.close()
def testchac(chac):
if chac>0x1F and chac<0x40: return chac #excludes @ 0x40
elif chac>0x40 and chac<0x7B: return chac
elif chac==0xE0: return chac # à
elif chac==0xE2: return chac # â
elif chac==0xE7: return chac # ç
elif chac==0xE8: return chac # è
elif chac==0xE9: return chac # é
elif chac==0xEA: return chac # ê
elif chac==0xEB: return chac # ë
elif chac==0xEE: return chac # î
elif chac==0xEF: return chac # ï
elif chac==0xF4: return chac # ô
elif chac==0xF9: return chac # ù
elif chac==0xFB: return chac # û
elif chac==0xA9: return 0x63 #copyright chac;
elif chac==0x0D: return 0x40 #CR
return 0
#if 1==1:
#variables
a=[] #collects text string
b=[] #collects addresses
c='' #collects tentative string
d=0 #counts number of strings processed
e=[] #collects string lengths
g=0 #counts string length
h=0 #counts num chacs processed
j=0 #collects tentative address
a.append('')
while end-1 > h:
#check for end string plus prep for next
if testchac(fb[h])==0:
if len(c)>2:
a[d]+=c
d += 1
a.append('')
e.append(g-1)
b.append(j)
g=0
c=''
j=h
else: c += chr(testchac(fb[h])) #copies all chacs to string
g += 1
h += 1
e.append(g)
#for once in range(1):
w = open('C:\Extraction\extractALL.txt','wt')
w.write('flag\taddress\tchaclen\tstring\ttranslate\n')
for i in range(d):
dump = w.write('0\t')
dump = w.write(str(b[i]))
dump = w.write('\t')
dump = w.write(str(e[i]))
dump = w.write('\t')
dump = w.write(a[i])
dump = w.write('\n')
w.close()If that can help EDIT : Pffff here it is 18:00 I have translated until line 1027 on 2970  so boared I'll make a break. Already around 15 hours of work !!! I can't just copy/past the FR text cause there is never enough char reamining ! The most difficult is when I havn't enough room for the little words... Try to translate "Fit" or "Exit" or "Lock" with only 4Char in FR  There are some words that will stay in Eng... |
|
|
|
Post by sushi on Feb 13, 2013 12:11:38 GMT -5
My dream ?
Having a programm that modify the HardwarW.exe and add 10chars to every string !!! That would be so cool !!!
|
|
|
|
Post by duncan on Feb 14, 2013 3:13:11 GMT -5
...suddenly a strange looking fellow appeared in your dream, he mumbled words like 'too long, shorter, longer, more translation work, see the pathcher thread' and the dream was no more, it had turned into a nightmare...
|
|
|
|
Post by sushi on Feb 14, 2013 18:35:52 GMT -5
lol All errors corrected ! The translation continues... Line 1566, there are a lot of redundancies I could have already finished... EDIT : Just finished ! 3h20 AM ! I go to bed now... Good night ! |
|
|
|
Post by sushi on Feb 15, 2013 12:30:17 GMT -5
Hello all, My translation is Over, now I'll try to apply it with the Ouch Patcher... I give you my spreadsheet in attachment. Please forgive the spelling errors in the FR translation, some string have so few chars available that some words are approximative  Maybe this will be fixed later... To work fast please sort the lines by "String" and resort by "Adress" when you're finished. @+ - Français - Salut à tous, Ca y est ma traduction est finie. Maintenant je vais essayer de l'appliquer avec le patcher de Ouch. Je vous mets ma feillle Excel en pièce jointe. Pardon pour les fautes d'orthographes que vous pourriez relever, parfois, le nombre de charactères disponibles était si faible et l'abbréviation si peu significative que j'ai choisi une traduction "phonétique"... Peut être que ça évoluera à l'avenir... Triez les lignes par "String" pour traiter tous les doublons en une seule fois, vous gagnerez un temps précieux. Retriez en suite per "adresses pour retrouver le classement original. @+ Sushi Attachments:
|
|
|
|
Post by sushi on Feb 16, 2013 7:50:18 GMT -5
Duncan, I've just re extracted the strings from the UIM06 HardwarW.exe installed on C: on my PC. So the same as your in fact. There is a pb with the addresses. They don't match. Each string extracted seems to have his address +1. Here is a printscreen to see what I mean... 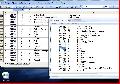 How can I fix that ? |
|
|
|
Post by duncan on Feb 16, 2013 13:30:55 GMT -5
Duncan, I've just re extracted the strings from the UIM06 HardwarW.exe installed on C: on my PC. So the same as your in fact. There is a pb with the addresses. They don't match. Each string extracted seems to have his address +1. Here is a printscreen to see what I mean... How can I fix that ? I guess it is just a matter of starting to count at 0 or at 1. Just keep in the back of your mind. If it turns out to be real a problem then just add 1 to the address value. A suggestion. Don't try all translations at once the first time, but just a few that you know you will see in the game. When that works do the rest. |
|
|
|
Post by sushi on Feb 16, 2013 14:15:35 GMT -5
Ok it is a good idea. As soon as I'm able to change my translations into Hex I try it.
Unfortunately, for the moment I didn't find how to convert Text in Hex into Excel...
|
|
|
|
Post by duncan on Feb 17, 2013 3:59:15 GMT -5
you dont need to change the translation text into hex, only the decimal address needs to be hex, at least that is what I understand from Ouch's writings.
|
|
|
|
Post by sushi on Feb 17, 2013 4:45:28 GMT -5
Ok great thanks ! I understand now |
|
|
|
Post by sushi on Feb 17, 2013 7:19:14 GMT -5
So it doesn't work ! Cause I'm not an informatician, it is far too complicated for me I spend too much time just to try to understand the way to use the patcher and the others tools, there is no way to paste more than 21 lines in one time and event with 21 lines here is the result.  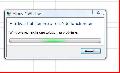 Ouch, thank you for all your precious help but unfortunately I haven't the knowledge to follow you and each step increases the difficulty... Maybe, when you have the time to do it, you make a new tab in your patcher, dedicated to the translation, with a tool to extract the strings ready to past into a spreadsheet to do the translation job and in this new tab, 3 columns to paste addresses, original string and translation. He he, just waiting for your brand new release  @+ |
|
|
|
Post by ouch on Feb 17, 2013 13:33:17 GMT -5
Ok, so with the new editor I've made some improvements based on what you guys need. First off the copy and paste has been fixed. Not only did it crash the program when you pasted out of bounds, but it also actually pasted hidden, invalid bytes as well causing all kinds of issues. But I have good news, I entered the first 3 pages of your translations Sushi to see if there were any more bugs with my patcher that you might run into and... sites.google.com/site/ouchsdownloads/home/downloads/french%20uim06.jpgA screen shot of the first partially translated version of UIM06.  you can get the file here if you want to try it yourself: sites.google.com/site/ouchsdownloads/home/downloads/UIM06%20String%20Translations.zipJust import the 12 pages in there and click patch for each of them. Which brings me to my first issue... There are going to be like 40 pages to patch. So I'm going to add a "patch all" button up at the top so that all of them can be applied at one time. Additionally I'm going to make an import all button so that importing all of these is easier as well. You can hold down shift or ctrl to select multiple pages under a table/version name to speed things up for now however. To make this I edited your spreadsheet which you can get here: sites.google.com/site/ouchsdownloads/home/downloads/HWFR.zipYou will see on the other sheets that I have formulas in place that do all the conversions and rearranges everything for you so that you can literally just copy and paste stuff into the editor. But keep in mind that these 2 sheets are reading the first sheet. So don't go changing a translation on sheet 2, change it on sheet 1 and everything will get converted back on sheet 2 for you. Right now the formulas on sheet 2 just create 3 columns creating a set. And each page in the editor consists of 3 sets. I can change this so that what you see there is a whole page ready to be copied and pasted. but I didn't do that because of some other issues below... The size of the strings are not correct. Some sizes don't include the terminator and some do... Furthermore there are some strings reported to have a max size of like 7 but they actually have like 20 or so. So because of the new byte limiter I have implemented in this version of my patcher it's going to result in some of the default strings getting cut off because the formula to get the max length is "max size-1". So for example the string CPU had a max length of 3 (it's really like 25) so what gets calculated is 2 and what got patched to the game was CP... so I had to change it. This occurred for an internal file string as well resulting in hardwar crashing. So Duncan, is there anyway you can get that script of yours to count the number of blank bytes after the string? it would be very handy if you could. Another thing is that the 0D issue from what I can see appears to actually be typos... No really, if you look at the MPH string you will see a 0D separating the speed from the string. If you replace that 0D with say the @ symbol, the @ symbol gets displayed in game. so the 0D is just being rendered as a space in game like any text editor would do... My theory is that they are just left over from a printf statement or something. Think about it though, even SR didn't have the ability for users to change Hardwar's language without an uninstall and reinstall of the game. When we are done, for the first time in the games history will a person be able to select which language they want from a drop box and click "patch all" to change it. And if they want to go back to the original they can just select the english version and then click patch all again. We're so close to pulling this off that you can almost taste the croissants... lol |
|
|
|
Post by sushi on Feb 17, 2013 15:37:43 GMT -5
Ok so It works ! Yahoooooo.... That's wonderful ! I'm very happy to read and see it. first of all, could you solve the string lenght question with Duncan so I can finalize the translation and correct all the errors. And maybe, if I understand what you explain, get some more char on some words Could be helpful... But on the other hand, maybe some words with less char !!! So I'll download your sheet and try to past all to see the issues.EDIT : Wahouu easier to say than to do... I'll wait patiently for the new version Got to read all this once againe to understand all the procedure. I give u a feedback as soon as I have any result. In order to optimize the copy/past Question : Why keep the Char len column ? Is it useful other than for the needs of the translation ? Question 2 : There is no need to copy/past the words that stay the same as the original. Can I sort the column of o/1 and copy only the translated words ? |
|





 so boared I'll make a break.
so boared I'll make a break.
 Maybe this will be fixed later...
Maybe this will be fixed later...





